アンケート分析(5):決定木
決定木でのビジュアル化
決定木は、「けっていぎ」と読むらしいです。
クラスタの各グループの意味を知るには、決定木が理解しやすさを提供してくれる。
今回も、こちらを参考にさせて頂きました。
実際のコード
#決定木のおまじない
import numpy as np
from sklearn import tree#正解データ=クラスタIDを格納
y = np.array(questionnaire["cluster_ID"].values)
#パラメター格納
X = questionnaire.drop("cluster_ID",axis=1).values
#4階層で設定
dtree = tree.DecisionTreeClassifier(max_depth=4)
#学習
dtree = dtree.fit(X,y)
ホントは、訓練データと検証データを分割するのでしょうが、サンプルも少ないので、学習のみさせています。
決定木表示のおまじない
import pydotplus
from IPython.display import Image
from graphviz import Digraph
dot_data = tree.export_graphviz(
dtree, # 決定木オブジェクトを一つ指定する
out_file=None, # ファイルは介さずにGraphvizにdot言語データを渡すのでNone
filled=True, # Trueにすると、分岐の際にどちらのノードに多く分類されたのか色で示してくれる
rounded=True, # Trueにすると、ノードの角を丸く描画する。
feature_names= questionnaire.columns[0:-1], # これを指定しないとチャート上で特徴量の名前が表示されない
class_names=y.astype("str"), # これを指定しないとチャート上で分類名が表示されない
special_characters=True # 特殊文字を扱えるようにする
)graph = pydotplus.graph_from_dot_data(dot_data)
graph.write_png("dtree.png")
Image(graph.create_png())
グラフ化のところが理解できていないので、コードをそのままコピペしております。
これを実行すると、以下の決定木が表示される。
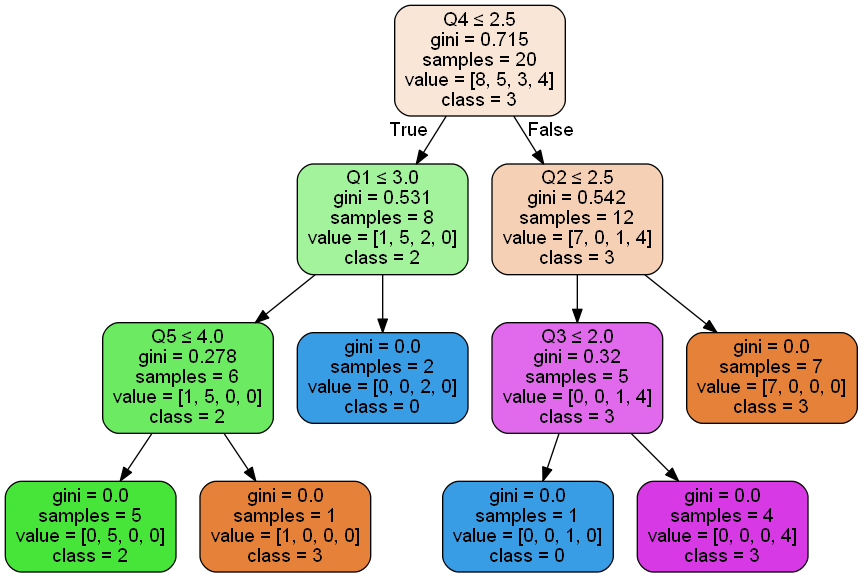
Q4で1-2で回答するか、3-5で回答するかで、8個と12個に、まず大きく分かれる。
「samples」が対象データの個数を表しています。
でも、このグラフにクラスタID=1がない。。。
決定木の各項目の意味など、こちらの説明が詳しく、分かりやすかったです。
改めて見直すと、クラスタID=1は5人いる。
一番上の四角のvalue=[8, 5, 3, 4]の部分で、左からクラスタIDが0~3の所属数を示している。
Q4の回答が1-2で8人に絞られ、Q1の回答が1-3で6人に絞られ、Q5の回答が1-4の5人がクラスタID=1と分類しているようです。
こんな感じでビジュアル化されるので、どのクラスタに属する人を増加させるためには、どの質問に対する対策をすればよいかが、分かる、はず。