SQLインジェクションの検出(エントロピー編)
ログ情報の数値化
こちらの書籍の7章にSQLインジェクションの検出方法が記載されている。

GitHub - oreilly-japan/ml-security-jp: 『セキュリティエンジニアのための機械学習』のリポジトリ
使用されているデータセットがこちらのHTTPリクエストのログ。
データの概要としては、
- 通常データ:19,304件
- 異常データ:11,763件
異常データの内訳は、
- SQLインジェクション:10,852件
- クロスサイトスクリプティング:532件
- コマンドインジェクション:89件
- パストラバーサル:290件
となっている。
ある程度、WEBアプリケーションの脆弱性に対する攻撃知識があれば、特定の文字列によって推測できるものもある。例えば、SQLインジェクションであれば、シングルクォーテーションの記号などが該当する。
書籍の中では、そのようにドメイン知識に基づいて特徴量を追加することと、単純に文字列を数値化する方法として、エントロピーを算出していた。
それ以外に、ドメイン知識に基づかない方法としてN-gramが紹介されていた。
エントロピーについて
シャノンのエントロピーを使って数値化します。公式は以下、というところでいきなり躓きます。

上記の式を分解していく。
この値は、情報量と確率(P)をかけたものの総和。
情報量は以下の公式で算出される。

確率(P)の算出方法について。
例えば、AAABCDEFGH、という8種類の文字からなる10桁の文字列があると仮定する。
1文字づつに区切って出現回数を算出すると以下になる。
A:3回
B~H:1回
これを文字数の10で割ると、文字の出現率、という確率(P)にできる。
A:0.3
B~H:0.1
情報量は、
A:1.73(-log₂0.3)
B~H:3.32(-log₂0.1)
となる。
エントロピーは、
A(0.3x1.73)+B(0.1x3.32)+C(0.1x3.32)+D(0.1x3.32)+E(0.1x3.32)+F(0.1x3.32)+G(0.1x3.32)+H(0.1x3.32)
=2.834
と計算される。
この計算を用いて、HTTPログのクエリ文字のエントロピーを算出して、文字列を数値化して、機械学習に使います。
以下がそのPythonのコード。
import numpy as np
import pandas as pd# HTTPクエリストリングのエントロピーの計算
def H_entropy(x):
prob = [ float(x.count(c)) / len(x) for c in dict.fromkeys(list(x)) ]
H = - sum([ p * np.log2(p) for p in prob ])
return H
以下のサイトでは、説明付きで別のコードが紹介されています。
実際にSQLインジェクションのデータと、通常のデータとではエントロピーの分布が異なる。
SQLインジェクションのデータの方がエントロピーが大きくなってたが、その理由がイマイチ良く分からない。
まとめ
特徴量エンジニアリングの一つとして、ログファイルの文字列からエントロピーを算出して数値化できる。
サイバー・フィジカル・セキュリティ対策フレームワーク(CPSF)
Society5.0
2019年4月に経済産業省は、サイバー・フィジカル・セキュリティ対策フレームワーク(CPSF)を策定した。
その前提となってるのが、Society5.0という考え方。
Society5.0は、2016年に閣議決定された「第5期科学技術基本計画」の中で、日本が目指すべき未来社会として提唱された。
サイバー空間とフィジカル空間を高度に融合させることにより、
多様なニーズにきめ細かに対応したモノやサービスを提供し、
経済的発展と社会的課題の解決を両立する超スマート社会
具体例として、以下のようなものが挙げられている。

引用:https://www8.cao.go.jp/cstp/society5_0/society5_0-2.pdf
そのような状況下では、サプライチェーンの在り方も変わってくる。

引用:https://www.meti.go.jp/policy/netsecurity/wg1/CPSF_ver1.0.pdf
「Society5.0」型のサプライチェーンをこれまでの定型的・直線的なサプライチェーンとは区別して認識するため、『価値創造過程(バリュークリエイションプロセス)とする。)』と定義している。
自社だけで価値創造をすることが難しい状況では、自社だけのセキュリティ確保は意味を持たなくなる。
三層構造と6つの構成要素
CPSFでは、バリュークリエイションプロセスが発生する産業社会を以下の3つの層で捉える。
第 1 層- 企業間のつながり
第 2 層- フィジカル空間とサイバー空間のつながり
第 3 層- サイバー空間におけるつながり

引用:https://www.meti.go.jp/policy/netsecurity/wg1/CPSF_ver1.0.pdf
その三層構造の構成要素が以下の6つとなる。

引用:https://www.meti.go.jp/policy/netsecurity/wg1/CPSF_ver1.0.pdf
それらをベースに、セキュリティ対策をまとめると以下になる。

引用:https://www.meti.go.jp/policy/netsecurity/wg1/CPSF_ver1.0.pdf
具体的な取り組み
以下CPSFの展開状況がまとめられている。
ビル・スマートホームなどへのガイドラインが作られていたりする。
最近では、工場システムに対するガイドラインへのパブリックコメントが募集されている。
やはり自動車に対するガイドラインを期待してしまいますが、作成されるのは、もう少し先なんでしょうか?
異常検知の方法(時系列編)
異常検知のソリューション
SIEM(Security Information and Event Management)やUEBA(User behavior analytics)などにより、脅威を早期に発見できる、という話を聞く。
IAM(Identity and Access Management)なども賢いものだと、異常なログインと判断して、追加の認証を求めたりするものもある。
裏側では、従来の統計的な手法や機械学習を用いたものがある、と想像できる。
いろんなログデータから異常を見出す方法は、セキュリティに有益なので、その具体的な方法を見ていく。
異常の発見方法
そもそも異常とは?
一般的には以下の3つに分類される。
-
点(ポイント/グローバル)異常:他からあまりにもかけ離れた単一のデータを指します。
-
文脈(コンテキスト)異常:あるデータセットのコンテキストでは異常であり、別のデータセットのコンテキストでは正常である異常を指します。時系列データのコンテキスト上の異常の中で最も一般的なタイプです。
-
集合的異常:データのサブセット全体が、より広範なデータセットと比較して異常である場合です。集合的異常を特定する際、個々のデータポイントは考慮されません。
引用:https://www.servicenow.com/jp/products/it-operations-management/what-is-anomaly-detection.html
ここでは、一番シンプルな点異常について、時系列データを使用して、検知する方法を見ていく。
時系列分析
時間の経過に沿って観測・記録されたデータは時系列データ、と呼ばれる。
時系列データのもつ傾向を分析する手法が時系列分析となる。
その傾向の基本的な変動要因が4つある。
- 傾向変動(T : Trend)
- 循環変動(C : Cycle)
- 季節変動(S : Seasonal)
- 不規則変動(I : Iregular or Noise)
これらの4つの要因の組み合わせに、2つのモデルがある。
- 加法モデル:T + C + S + I
- 乗法モデル:T x C x S x I
これにより、未来の予測やモデルに当てはまらないものを異常値と判断する根拠にする。
Windowsドメインへのログイン異常検知
Windowsのドメインコントローラーでのログインログから異常値を検出する具体例が以下にある。
この中で、Anomaly detection and visualization using Time Series Decomposition として、サンプルデータとともに、Pythonのコードが紹介されている。
ステップとしては、以下の通り。
1.日付毎のログイン数を集計する。

2.STLによる時系列分析を実施
ここでは、
def tsa_using_stl(data,score_threshold):
という独自関数で定義している。別の方法として、
from msticpy.analysis.timeseries import timeseries_anomalies_stl
STL_df= timeseries_anomalies_stl(timeseriesdemo_agg, seasonal=31)
とすることで同等の結果が得られる。
裏では、STL分解(Seasonal Decomposition Of Time Series By Loess)を実施。
LOESS平滑化(locally estimated scatterplot smoothing)というノンパラメトリック回帰モデルを利用している、らしい。
元データ = トレンド + 季節性 + 残差
3.描画
timeseries_anomalies_plot = display_timeseries_anomolies(data=STL_df, y="TotalLogons",time_column='Date')
として、異常を表示するグラフの出来上がり。

まとめ
ログオンのログが周期性がある、という前提でその周期性からはみ出すログを抽出した。ここまでやらなくても、普通に集計しても分かりそうなもの。
点異常だけでなく文脈異常についての実現方法が気になってくる。
ダイアモンドモデル
ダイアモンドモデルについて
CEH v12では、ダイアモンドモデル、の内容が追加されている、とのことだった。
侵入を分析し、記述する方法らしいので、まとめておく。
2013年に発表された「Diamond Model of Intrusion Analysis」という論文がもとになっている。
Adversary,Infrastructure,Capability,Victimという4つの要素からなり、その要素間に「イベント」を定義して、分析していくモデル。

diamond-model.pdf (threatintel.academy) から引用
具体的なマルウェアの感染例の図。
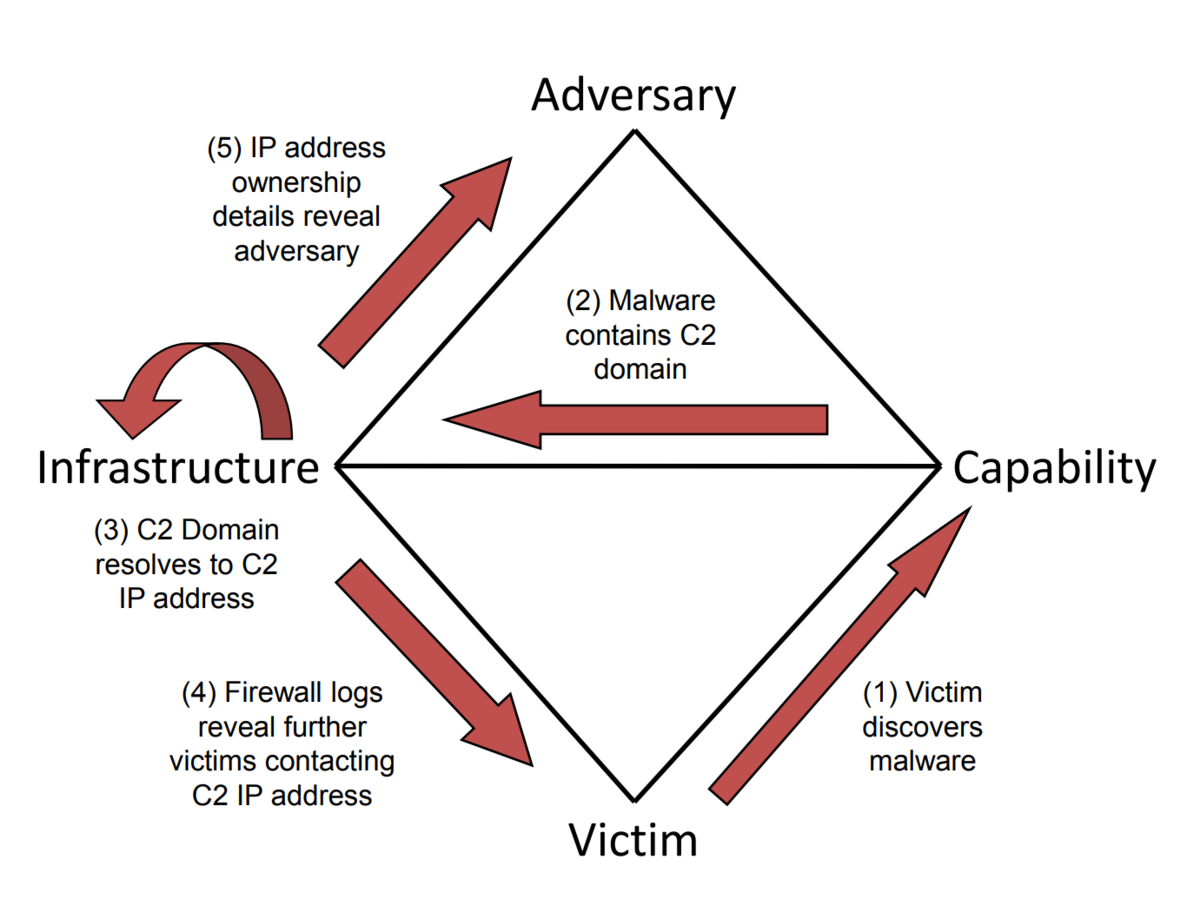
diamond-model.pdf (threatintel.academy) から引用
イベントをCyber Kill Chainのフェーズ上にプロットして、「アクティビティスレッド」として表現したものが以下になる。
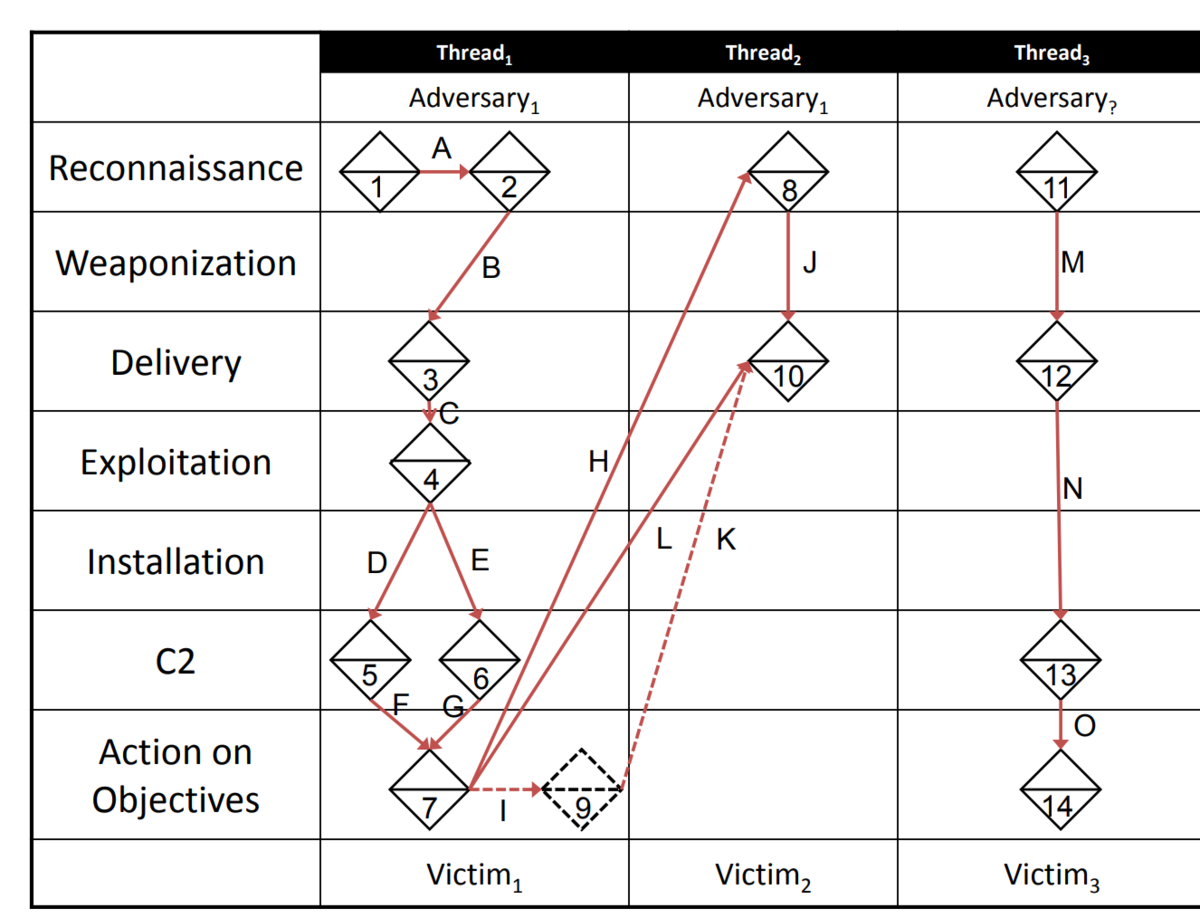


という感じで、ミクロモデルとして、インシデントの表現方法としてのダイアモンドモデル、という捉え方以外にも、グラフ化して過去の事例を検索しやすくする試みも。
https://www.ipsj.or.jp/award/9faeag0000004f4v-att/L-015.pdf

マクロモデルとして、インシデントの概要を示すためにも使用される。
一番分かりやすい例は、スターウォーズを題材にしたこちら。

引用:https://threatconnect.com/blog/diamond-model-threat-intelligence-star-wars/
攻撃者がルークで、X-WINGに乗って、ブラスターやフォースという能力を用いて、デススターが被害者になっているのが面白い。モチベーションは復習で、攻撃手法はフォースによる操縦とコミュニケーション。
インシデントの表現では、被害者・攻撃者どちらかに偏りがちになってしまうが、ダイアモンドモデルでは、俯瞰的に表現できるのが良いと思う。
ディープラーニングによるマルウェア検出(実行編)
前回のおさらい
以下の記事で、EXEファイルを画像化することをやった。
これにより、マルウェアを画像化して、AIに「似ている」ということを判断させることが可能になる。
データは以下を利用させてもらう。
このデータは、
マルウェア名のフォルダに、そのマルウェアの画像が含まれている。

画像データの数値化処理
テレビと同じような原理で、映像を碁盤目に分けて、その1マス(画素)の色を数値化する。カラーの場合はRGBなので、(12, 34, 56)という3次元で表現される。
白黒の場合は、ゼロかイチかで表現できる。
例えば、2x2マスの白黒画像を数値化すると、以下のようになる。

2x2マスの白黒画像=[1,0,0,1]と表現できる。
実際は、もっと大きい画素で、ゼロとイチではなく、黒が占める割合で表現される。
画像ごとに処理を行いデータを作ることになる。
こんなコードを書けば、一発でやってくれてしまう。
from keras.preprocessing.image import ImageDataGenerator
#Generating DataSetpath_root = "malimg_paper_dataset_imgs\\"batches = ImageDataGenerator().flow_from_directory(directory=path_root, target_size=(64,64), batch_size=10000)imgs, labels = next(batches)
target_sizeは画像のサイズで64x64の画像に縮小している。
labelsにマルウェアの名称が入るが、それはフォルダ名をセットしてくれる。
ディープラーニングでの処理
上記データをもとにディープラーニングによるマルウェア検出器の作成。
データの分割
from sklearn.model_selection import train_test_splitX_train, X_test, y_train, y_test = train_test_split(imgs/255.,labels, test_size=0.3)
モデルの作成
import kerasfrom tensorflow.keras import Inputfrom tensorflow.keras.layers import BatchNormalizationfrom keras.models import Sequential,Modelfrom keras.layers import Dense, Dropout, Flattenfrom keras.layers import Conv2D, MaxPooling2D
num_classes = 25
Malware_model = Sequential()activation='relu',input_shape=(64,64,3)))
Malware_model.add(Flatten())
Malware_model.summary()
2次元畳み込み層を使って、プーリング層を追加し、Flattenで一次元に変換しています。

訓練の実行
検証
scores = Malware_model.evaluate(X_test, y_test)

検証結果は、95.43%の精度が出ました。
まずまずの結果がでます。
まとめ
マルウェアを画像化したデータを使って、ディープラーニングによるマルチクラス分類を実装したら、95.43%の精度がでました。
参考サイト
殆ど、内容を端折って、こちらのコードを借用しております。一部、インポート文を修正しております。
ディープラーニングによるマルウェア検出(準備編)
ディープラーニングの使いどころ
相変わらず、以下の書籍を参考にさせて頂いております。
以前、PEファイルの情報をランダムフォレストで分類させることをやった。
PEファイルをディープラーニングで分類させることも可能。
ディープラーニングの場合、スケーリング化する必要がある。
PEファイルに対しては、標準化を行っていた。標準化の場合は、StandardScalerを使い、平均0、標準偏差1のデータに変換する。
from sklearn.preprocessing import StandardScaler# 訓練用とテスト用の特徴量を標準化scaler = StandardScaler()X_train = scaler.fit_transform(X_train)X_test = scaler.transform(X_test)
正規化は、MinMaxScalerを使って、0から1の間に値を変換する。
from sklearn.preprocessing import MinMaxScaler# 訓練用とテスト用の特徴量を正規化scaler =MinMaxScaler()X_train = scaler.fit_transform(X_train)X_test = scaler.transform(X_test)
書籍では、EMBERデータセットを用いて、Kerasを使った分類を行っていた。
EMBERは、データセットのみならず、マルウェア検出のスクリプトなども提供されているようです。こちらの情報が詳しかった。
ここまではPEファイルの情報を扱っているが、ディープラーニングの得意な画像を使った判定がある。
マルウェアの画像化
マルウェアをそのまま利用するには、感染のリスクが伴う。PEファイルの情報以外に、マルウェアのバイナリ情報を画像に変換することが行われている。
実行ファイルの画像化は、Pythonでは以下のコードになる。
import osimport numpy as npimport imageioimport array
filename = 'calc.exe'f = open(filename,'rb')ln = os.path.getsize(filename)width = 256rem = ln%widtha = array.array("B")a.fromfile(f,ln-rem)f.close()g = np.reshape(a,(len(a)//width,width))g = np.uint8(g)
計算機アプリ(calc.exe)を画像に変換すると、以下のイメージができる。

こんな画像を、マルウェア別に提供してくれているデータセットが以下。
25種類のマルウェアファミリ、9339件の画像データ。
Kaggleでは、画像化する前のバイナリのデータセットがコンペで使われていた。
実行ファイルをバイナリファイルにする方法が理解できていない。
バイナリファイルを画像にするには、以下のサイトにコードが掲載されている。
そのままだと動かないので、少し修正させてもらいました。
import matplotlib.pyplot as pltimport numpy as npfrom PIL import Image
## フォルダのパスroot = 'dataSample'
## This function allows us to process our hexadecimal files into png images##def convertAndSave(array,name):print('Processing '+name)if array.shape[1]!=16: #If not hexadecimalassert(False)b=2**(int(np.log(b)/np.log(2))+1)a=int(array.shape[0]*16/b)array=array[:a*b//16,:]array=np.reshape(array,(a,b))im = Image.fromarray(np.uint8(array))return im
#Get the list of filesfiles=os.listdir(root)print('files : ',files)#We will process files one by one.for counter, name in enumerate(files):#We only process .bytes files from our folder.if '.bytes' != name[-6:]:continuef=open(root+'/'+name)array=[]for line in f:xx=line.split()if len(xx)!=17:continuearray.append([int(i,16) if i!='??' else 0 for i in xx[1:] ])plt.imshow(convertAndSave(np.array(array),name))del arrayf.close()
マルウェア名のフォルダに、該当する画像ファイルを作成すれば、ディープラーニングによる、画像分類タスクでマルウェアを分類することができるようになる。
次回、実際にディープラーニングでのマルウェア検知を実装してみる。
*1:array.shape[0]*16)**(0.5
機械学習によるマルウェア判定(PEファイル)
PEファイルのおさらい
PEファイルについて、以下を参照。
マルウェアの検体を取得する方法は以下を参照。
PEファイルの情報は、pefileというpythonのライブラリで取得できる。
問題のない正常なファイルはPCにいくらでもあるので、ディレクトリを再帰的に処理して、情報を取得すれば良い。ただ、それを上手に正規化されたデータに落とす方法を見つけることが出来なかった。
そういうデータセットを作成してくれている人がいるようで、Prateek Lalwaniという人が公開している、とのことですが、そのgithubはクローズされています。
ただ、他の人のgithubには公開されているので、そのデータを借用します。
以下2つのサイトで、MalwareData.csvのデータが取得できます。
上記は、そもそも、こちらの本を参考にさせてもらっていて、そのgithubサイトです。
どちらのサイトも、ファイルだけでなく、Pythonでの機械学習のコードがあります。
Kaggleにもデータがありますが、上記と同じもののようです。
データについて
データの取り込み
上記によりデータセットへ取り込みます。データは138047 rows × 57 columnsという内容。
MalwareDataset.columns
から、カラムを出力してみると、以下の57カラムであることが分かる。
Index(['Name', 'md5', 'Machine', 'SizeOfOptionalHeader', 'Characteristics', 'MajorLinkerVersion', 'MinorLinkerVersion', 'SizeOfCode', 'SizeOfInitializedData', 'SizeOfUninitializedData', 'AddressOfEntryPoint', 'BaseOfCode', 'BaseOfData', 'ImageBase', 'SectionAlignment', 'FileAlignment', 'MajorOperatingSystemVersion', 'MinorOperatingSystemVersion', 'MajorImageVersion', 'MinorImageVersion', 'MajorSubsystemVersion', 'MinorSubsystemVersion', 'SizeOfImage', 'SizeOfHeaders', 'CheckSum', 'Subsystem', 'DllCharacteristics', 'SizeOfStackReserve', 'SizeOfStackCommit', 'SizeOfHeapReserve', 'SizeOfHeapCommit', 'LoaderFlags', 'NumberOfRvaAndSizes', 'SectionsNb', 'SectionsMeanEntropy', 'SectionsMinEntropy', 'SectionsMaxEntropy', 'SectionsMeanRawsize', 'SectionsMinRawsize', 'SectionMaxRawsize', 'SectionsMeanVirtualsize', 'SectionsMinVirtualsize', 'SectionMaxVirtualsize', 'ImportsNbDLL', 'ImportsNb', 'ImportsNbOrdinal', 'ExportNb', 'ResourcesNb', 'ResourcesMeanEntropy', 'ResourcesMinEntropy', 'ResourcesMaxEntropy', 'ResourcesMeanSize', 'ResourcesMinSize', 'ResourcesMaxSize', 'LoadConfigurationSize', 'VersionInformationSize', 'legitimate'], dtype='object')
「legitimate」カラムがマルウェアかどうかの判定になっており、
- 1:正常ファイル
- 0:マルウェアファイル
という分類がされている。
でデータをカウントしてみると、
0:96724
1:41323
ということで、マルウェア多めのデータとなっている。
ここまでデータがあれば、あとは機械学習の分類アルゴリズムを適用できる。ただ、上記サンプルでは、機械学習の前に、ExtraTreeを使って、分類に寄与するパラメーターを絞って学習させることで、分類精度を上げることが可能になる。
つまり、どのPEヘッダーの情報がマルウェアの分類に影響するのか把握できる。
以下のコードにより、
(138047, 57) (138047, 13) が出力され、13個の特徴量が分類に大きな影響を与えることがわかる。
from sklearn.ensemble import ExtraTreesClassifierfrom sklearn.feature_selection import SelectFromModel
# 不要なカラムを削除
# データセットのラベル列のみを抽出してyに代入y = MalwareDataset['legitimate'].values
# ExtraTreesClassifierを使用extratrees = ExtraTreesClassifier().fit(X, y)
# SelectFromModelを使用して、# ExtraTreesClassifierによる分類結果に寄与した重要度の大きい特徴量のみを抽出selection = SelectFromModel(extratrees,prefit=True)
# 重要度の大きい特徴量のカラム名を取得feature_idx = selection.get_support()feature_name = X.columns[feature_idx]
new_data = selection.transform(X)new_data = pd.DataFrame(new_data)new_data.columns = feature_name#Checking the shape of old as well as new dataprint(MalwareDataset.shape,new_data.shape)
重要な特徴量を出力するコード
features = new_data.shape[1]
# 重要度をリストで抽出importances = extratrees.feature_importances_
# 重要度を高い順にソートindices = np.argsort(importances)[::-1]
# 重要度の高い順に、特徴量の名前と重要度を出力for i in range(features):print("%d"%(i+1),MalwareDataset.columns[2+indices[i]],importances[indices[i]])
上記コードにより、以下が出力される。
1 DllCharacteristics 0.15836263233530415 2 Machine 0.12007604719789777 3 Characteristics 0.10400284183445602 4 SectionsMaxEntropy 0.06542977624819674 5 Subsystem 0.059400268661077955 6 VersionInformationSize 0.057993969120311704 7 ImageBase 0.05571243209223071 8 MajorSubsystemVersion 0.047525009638160316 9 ResourcesMaxEntropy 0.043357550686231955 10 SizeOfOptionalHeader 0.029203678693686497 11 MajorOperatingSystemVersion 0.026403782923872843 12 SectionsMinEntropy 0.023331472771475084 13 ResourcesMinEntropy 0.0202876288981414
これは、ランダムに実行されるので、実行のたびに結果が異なる。
上記では、「DllCharacteristics」が特徴量として重要、ということになる。
あとは、以下のサイトからコピペさせてもらい、機械学習を実行。
optunaによる最適なパラメータの探索
from sklearn.ensemble import RandomForestClassifierfrom sklearn.metrics import accuracy_scorefrom sklearn.model_selection import train_test_splitimport numpy as npimport optunafrom sklearn.model_selection import cross_validate
# データセットを訓練用とテスト用に分割X_train, X_test, y_train, y_test = train_test_split(new_data, y, test_size=0.2, shuffle=True, random_state=101)
# RandomForestClassifierのハイパーパラメータ探索用のクラスを設定class Objective_RF:def __init__(self, X, y):self.X = Xself.y = y
def __call__(self, trial):# 探索対象のパラメータの設定criterion = trial.suggest_categorical("criterion",["gini", "entropy"])bootstrap = trial.suggest_categorical('bootstrap',['True','False'])max_features = trial.suggest_categorical('max_features',['auto', 'sqrt','log2'])min_samples_split = trial.suggest_int('min_samples_split',2, 5)1,10)
model = RandomForestClassifier(criterion = criterion,bootstrap = bootstrap,max_features = max_features,min_samples_split = min_samples_split,)
# 交差検証しながらベストのパラメータ探索を行うscores = cross_validate(model,X=self.X,y=self.y,cv=5,n_jobs=-1)# 5分割で交差検証した正解率の平均値を返すreturn scores['test_score'].mean()
# 探索の対象クラスを設定objective = Objective_RF(X_train, y_train)study = optuna.create_study()# 最大で3分間探索を実行study.optimize(objective, timeout=180)# ベストのパラメータの出力print('params:', study.best_params)
params: {'criterion': 'gini', 'bootstrap': 'False', 'max_features': 'auto', 'min_samples_split': 5, 'min_samples_leaf': 10}
ベストパラメータで学習
from sklearn.metrics import confusion_matrixfrom sklearn.metrics import accuracy_score
# optunaの探索結果として得られたベストのパラメータを設定model = RandomForestClassifier(criterion = study.best_params['criterion'],bootstrap = study.best_params['bootstrap'],max_features = study.best_params['max_features'],min_samples_split = study.best_params['min_samples_split'],)
# モデルの訓練model.fit(X_train, y_train)
# テスト用のデータを使用して予測pred = model.predict(X_test)
# 予測結果とテスト用のデータを使って正解率と、混同行列を出力print("Accuracy: {:.5f} %".format(100 * accuracy_score(y_test, pred)))print(confusion_matrix(y_test, pred))
Accuracy: 99.08367 % [[19338 128] [ 125 8019]]
ランダムフォレストでの特徴量の表示
%matplotlib inline
feat_importances = pd.Series(model.feature_importances_,index=new_data.columns).sort_values(ascending=True)
feat_importances.plot(kind='barh')

ここでは、「ImaegeBase」が重要なパラメータ、ということになっており、ExtraTreeの結果「DllChracteristics」と異なる。
ちなみに、ExtraTreeによるパラメータの削減をせずに、ランダムフォレストを実行した場合、Accuracy: 99.13799 %というスコアが出て、こちらの方が結果が良くなる。
これは過学習のせい、なのかもしれないが、その辺りの調査は必要。