Web Applications
Web applicationに関する情報
Web applicationに関するハッキング手法やツールについてまとめようとするが、とくにかく情報量が多い。
CEHのテキストでは、Web Applicationという章がテキストで300ページほどあり、それ以外に、セッション・ハイジャック、Webサーバのハッキング、SQLインジェクションなど、関連する内容が別の章立てとなっている。
CEHでは、以下のようなスタックの説明から、いろんな攻撃手法の説明、ツールの紹介となる。

https://exploitbyte.com/vulnerability-stack/ から転載させていただきました。
ツールの種類も豊富で、
- Vega
- WPScan
- Arachni
- appspider
- Uniscan
- Burp Suite
- WebScrab
- OWASP Zed Attack Proxy(ZAP)
- nikto
など全部書ききれません。
Kaliにインストールされているものもあれば、そうでないものもある。

ツールの選択
銀の銃弾はないとは言え、いろんな書籍やサイトで、言われているのは、まずは「Burp Suite」で、しかも、無料のCommunity Editionじゃなくて、有料版(399ドル)を。その価値はある、とのこと。
とりあえずCommunity Editionで慣れつつ、有料版の30日の無料トライアルを試しつつ、違いを把握しよう。
ツールは決まったが、何からすれば良いのか??
先達はあらまほしき事なり
いつも参考にさせて頂いているブログでタイムリーな記事がありました。
思いっきり端折りますが、
- OWASP BWA、bWAPP、OWASP Juice Shop、ONTRA OWASP Top 10などのヤラれサイトで勉強。
- PortSwiggerで、みっちり勉強、
- WSTGでの確認
というステップで、Burp Suiteの使い方、脆弱性診断に関する一通りの知識習得ができそうです。
長い道のりになりそうですが、知識を実践の場で活かせるようになるために、少しづつ進めていきたいとおもいます。
つ・づ・く
管理者アカウントの管理について
IDとパスワードの悩み
IDとパスワードの管理が、未だに良く分からない。
パスワード管理で良く言われる、以下の事は頭では理解できる。
- 数字・記号・アルファベット(大文字・小文字)を混ぜましょう
- 8文字以上の長さにしましょう
- パスワードの使いまわしはやめましょう
- 定期的に変更しましょう
全て出来る人がこの世に存在するのでしょうか?
最近では、開き直って、意味不明なパスワードを設定して、
都度、パスワード回復をしたほうが安全な気もしてきました。
個人用アカウントならまだしも、企業内で使用しているActive Directoryの管理者アカウントは、そういう訳にもいかない。
Active Directoryでのアカウント管理について
マイクロソフトからドキュメントが出ている。
かなり大雑把に要約すると、こんな感じ。
- Administratorアカウントを使用しない。
- Administrators、Domain admins、Enterprise Adminsの特権ビルトイングループを管理して、特権を最小限にするようにする。
- 特権アカウントを管理する特殊なアカウントを作成する
こちらも、頭ではわかります。全て出来る会社がこの世に存在するのでしょうか?
ドキュメントで説明するなら、デフォルトで実装しておいて、と言いたくなります。
特権ビルトイングループを保護するために、以下を実施とあります。
・ネットワークからこのコンピューターへのアクセスを拒否
・バッチ ジョブとしてのログオン権限を拒否する
・サービスとしてのログオン権限を拒否する
・リモート デスクトップ サービスを使ったログオンを拒否
物理サーバー環境ならわかりますが、仮想化が中心の世の中で、ネットワーク経由で仮想管理基盤にログインできるので、あまり意味がないのでは?と思ってしまう。
クラウドではMFA(多要素認証)が叫ばれている昨今、昔ながらの「スマートカード」も、物理サーバー前提か?
特権管理アカウントを管理するアカウントの管理をどうする?最終的に、いろんな権限の分散をしたアカウントの保護はどうする?という話に行きつく。
最終的に、そこは、監査をしっかりやりましょう、ということになるが、一体どれだけの手間がかかるのか。
少し前の資料では、パスワードに対して、パスフレーズを使用しましょう、とか、パスワードを複数人で分割して管理とかの記載があった。
上記から抜粋。
パスフレーズとは、基本的に "My son Aiden is three years older than my daughter Anna (息子の Aiden は娘の Anna より 3 歳年上)" のような記憶できる文章のことです。 文中の各単語の最初の文字を使用すると、かなり強固なパスワードを作成することができます。 この例の場合、"msaityotmda" になります。 しかも、大文字と小文字、数字、特殊文字などを組み合わせると、さらに強固なパスワードにすることができます。 たとえば上の文章に手を加えると、M$"8ni3y0tmd@ というパスワードになります。 パスフレーズは辞書攻撃に対して脆弱ですが、世間に出回っているほとんどのパスワード解読ソフトウェアは、14 文字を超える長さのパスワードをチェックしません。
まるで、日本人向きではありません。
話は振り出しに戻る
結局、パスワードがしっかり管理できれば、複雑な運用を避けられるのではないか。
パスワードを厳重な金庫に保管して、一部分を共有したり、アクセスを厳密にしたり、ログを把握できるようにする。ActiveDirectoryだけなく、他にも使える。
「1Password」というサービスが有名らしい。
ビジネスプランでは、特定のアカウントをグループで共有できるので、共有前提でアカウント管理ができる。また、パスワードの使いまわしもする必要がなくなる。
ここにログインするために、いろんな認証方法が選べるので、そこを集中的に管理すれば良くなる。
Active Directory以外のID・パスワード管理の運用も考えれば、この選択は必然なのか。
アンケート分析(5):決定木
決定木でのビジュアル化
決定木は、「けっていぎ」と読むらしいです。
クラスタの各グループの意味を知るには、決定木が理解しやすさを提供してくれる。
今回も、こちらを参考にさせて頂きました。
実際のコード
#決定木のおまじない
import numpy as np
from sklearn import tree#正解データ=クラスタIDを格納
y = np.array(questionnaire["cluster_ID"].values)
#パラメター格納
X = questionnaire.drop("cluster_ID",axis=1).values
#4階層で設定
dtree = tree.DecisionTreeClassifier(max_depth=4)
#学習
dtree = dtree.fit(X,y)
ホントは、訓練データと検証データを分割するのでしょうが、サンプルも少ないので、学習のみさせています。
決定木表示のおまじない
import pydotplus
from IPython.display import Image
from graphviz import Digraph
dot_data = tree.export_graphviz(
dtree, # 決定木オブジェクトを一つ指定する
out_file=None, # ファイルは介さずにGraphvizにdot言語データを渡すのでNone
filled=True, # Trueにすると、分岐の際にどちらのノードに多く分類されたのか色で示してくれる
rounded=True, # Trueにすると、ノードの角を丸く描画する。
feature_names= questionnaire.columns[0:-1], # これを指定しないとチャート上で特徴量の名前が表示されない
class_names=y.astype("str"), # これを指定しないとチャート上で分類名が表示されない
special_characters=True # 特殊文字を扱えるようにする
)graph = pydotplus.graph_from_dot_data(dot_data)
graph.write_png("dtree.png")
Image(graph.create_png())
グラフ化のところが理解できていないので、コードをそのままコピペしております。
これを実行すると、以下の決定木が表示される。
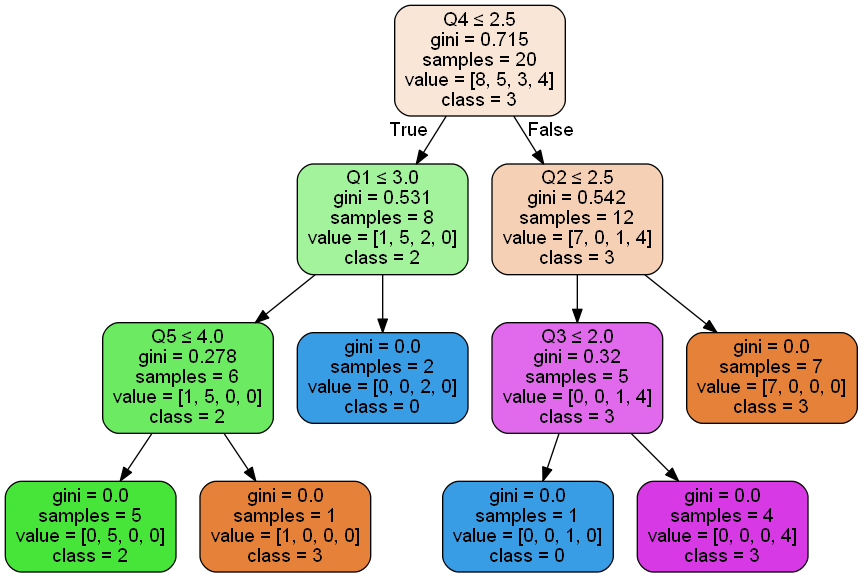
Q4で1-2で回答するか、3-5で回答するかで、8個と12個に、まず大きく分かれる。
「samples」が対象データの個数を表しています。
でも、このグラフにクラスタID=1がない。。。
決定木の各項目の意味など、こちらの説明が詳しく、分かりやすかったです。
改めて見直すと、クラスタID=1は5人いる。
一番上の四角のvalue=[8, 5, 3, 4]の部分で、左からクラスタIDが0~3の所属数を示している。
Q4の回答が1-2で8人に絞られ、Q1の回答が1-3で6人に絞られ、Q5の回答が1-4の5人がクラスタID=1と分類しているようです。
こんな感じでビジュアル化されるので、どのクラスタに属する人を増加させるためには、どの質問に対する対策をすればよいかが、分かる、はず。
アンケート分析(4):クラスタリング
クラスタ分析
クラスタリング 、クラスタ解析など呼ばれますが、データを一定のグループにまとめること。階層型と非階層型がある。
アンケート結果に対してクラスタ分析を行うことで、いくつかの傾向を読み取り、それに対してアクションを取ることを可能にしたい。
以下のサイトを参考にさせていただきました。
というか、ほぼコード流用です。
階層型クラスタリング
いくつくらいのグループに分けるのがいいのか、あらかじめ決まっていれば良いですが、ある程度、データからグループ数の参考を得たい。
その際は、樹形図(dendrogram デンドログラム)を使ってビジュアルに表現して、データの概要を把握する。
デンドログラムのコード
from scipy.cluster.hierarchy import linkage, dendrogram
import matplotlib.pyplot as plt
import seaborn as sns#ウォード法を使用
questionnaire_s_hclust = linkage(questionnaire_s,metric="euclidean",method="ward")
plt.figure(figsize=(12,8))
dendrogram(questionnaire_s_hclust)
plt.savefig('figure_1.png')
plt.show()

4つのグループに分けると、3、6、3、8個に分類される、という参考になる。
非階層型クラスタリング
ある程度、クラスタ数が決まれば、k平均法による非階層型クラスターに分割して、分析をすることで、それぞれのクラスタの解釈をする。
k平均法のクラスタリングは、教師無し機械学習、と呼ばれます。
実際のコード
k平均法のおまじない
from sklearn.cluster import KMeans
#クラスタ数を4に設定
km = KMeans(n_clusters=4,random_state=42)
クラスタリングして、結果を保存
#numpyの行列に変換
questionnaire_arr = questionnaire_s.values
#kmeansを適用した結果のグルーピングの配列が出力として渡される
questionnaire_add_pred = km.fit_predict(questionnaire_arr)
#元のデータにクラスタIDを追加
questionnaire["cluster_ID"] = questionnaire_add_pred
クラスタIDをカテゴリに変更して、集計する。
#カテゴリカル変数に変更
questionnaire["cluster_ID"] = questionnaire["cluster_ID"] .astype("category")
questionnaire["cluster_ID"].value_counts()
実際の実行結果

8,5,4,3個の4つのグループが出来ました。階層型クラスタリングと結果は異なりますが、ある程度バランスが取れている、ことにしておきます。
更なる分析
4つのグループの特徴=回答の偏りがどのあたりにあるのか、を知るために、データを再構成していく。
以下により、ダミー変数を使って、クロス集計表のようなものを作成する。
#全ての項目をカテゴリ化
questionnaire = questionnaire[:].astype("category")#ダミー変数化したい列を指定するために列名を取得してリスト化、更にクラスタIDを除く
dummy_list = list(questionnaire.columns)[0:-1]#ダミー変数化したい列名を指定して全ての設問をダミー変数化
questionnaire_dmy = pd.get_dummies(questionnaire, columns=dummy_list)

次に、クラスタ毎で集計する。
クラスタIDでグループ化し数値を集約します
questionnaire_dmy_gp = questionnaire_dmy.groupby("cluster_ID")#グループ別に各設問の回答者数の合計を出します
questionnaire_dmy_gp_g = questionnaire_dmy_gp.sum().T

少し見やすくしてみる
questionnaire_dmy_gp_g.style.bar(color="#4285F4")

Q1に対して、クラスタIDが0、2,3のグループは、1-3で回答しているが、1のグループは4-5で回答している、という違いが見える。
クラスタマップの出力
plt.figure(figsize=(12,8))
sns.clustermap(questionnaire_dmy_gp_g,cmap="viridis")
plt.savefig('figure_2.png')
plt.show()

なんとなく、分かったような、分からないような。。。
アンケート分析(3):データの水増し
データの水増し
データの水増しをアンケートでやったら偽造ですが、上手に機械学習させるために、少ないサンプルデータに対してよく行われている、とのこと。
特に画像認識系で、画像データが少ない場合など、ノイズを与えてデータを複製する。
後学のため、アンケートデータに対して実施。
data augmentationというらしく、こちらを参考にさせて頂きました。
データ水増しのステップ
1.データを標準化する
2.標準化したデータに対して主成分分析(PCA)を実施
3.PCAを復元する
これにより、単なる元データのコピーではなく、少し揺らぎのあるデータが取得できる。
実際のコード
以下の手順で、データが標準化されている前提です。
PCAのおまじない。あまり圧縮しすぎると復元できないので、1次元削減。
from sklearn.decomposition import PCA
#(元のカラム数=5 - 1)
n_comp = 4
pca = PCA(n_components=n_comp, random_state=42)
圧縮・復元・変換
#PCAによる圧縮
pca_res = pca.fit_transform(questionnaire_s)
#PCAの復元化
restore_list = pca.inverse_transform(pca_res)
#データフレームに変換
aug_data_df = pd.DataFrame(restore_list)
データフレーム変換前に標準化を戻すことも可。
#標準化を元に戻す
restore_list = restore_list*ss.scale_ + ss.mean_
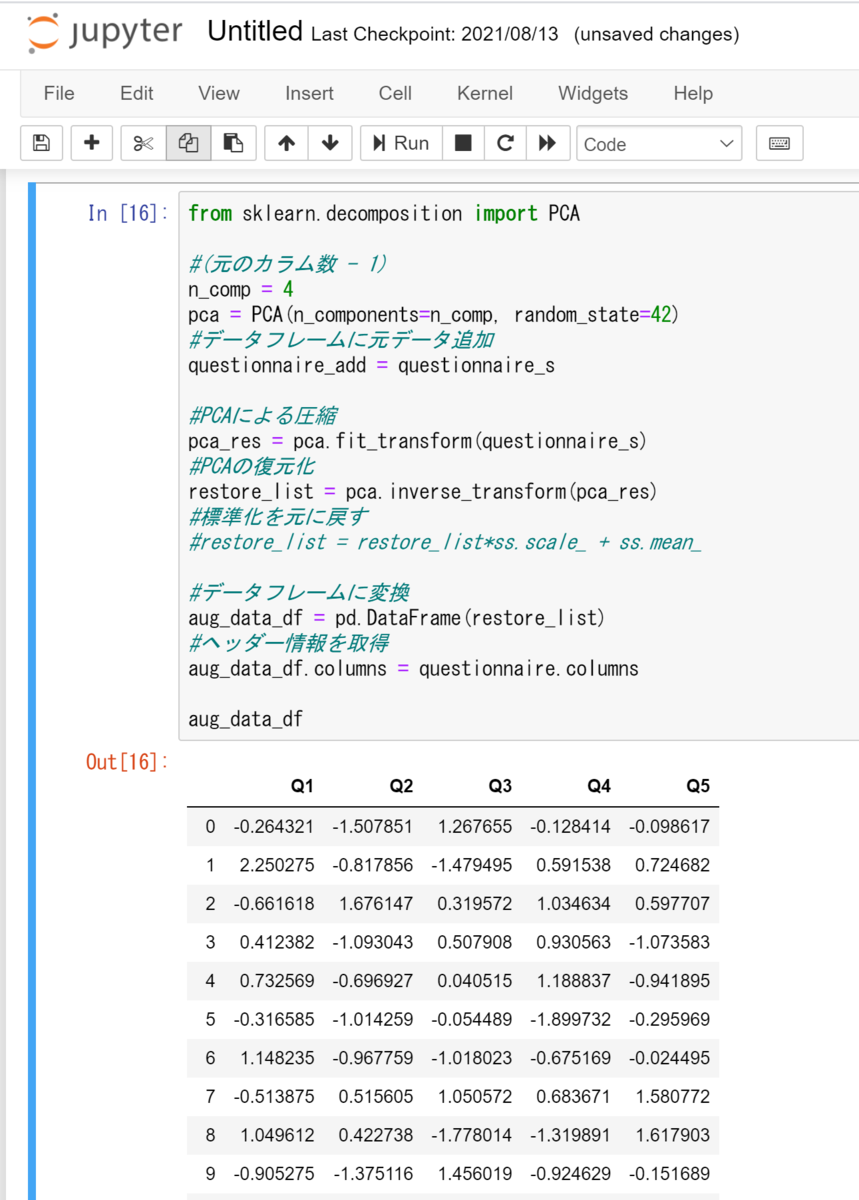
次元削減の主成分分析と因子分析は、どの説明を聞いても、未だ納得できないですが、データの水増しに使えることで、少し理解が進みました。
アンケート分析(2):スケーリング
スケーリングの目的
アンケートデータの場合、5段階の回答を求める場合、質問によっては、1に偏ったりする場合がある。各設問でばらつきがでないように調整するため。
スケーリングには、2種類ある。
- 正規化:「特徴量を0〜1に変換するスケーリング」
- 標準化:「特徴量の平均を0、分散を1に変換するスケーリング」
数式に書くと。。。眠たくなるので、割愛。
アンケートデータのスケーリングでは、分散を等しくするために、標準化を使う。
pythonでの実装
pythonのscikit-learnのsklearnを使えば、2-3行のコードで実現できる。
- MinMaxScaler:正規化
- StandardScaler:標準化
以下が実際のコード
from sklearn import preprocessing
ss = preprocessing.StandardScaler()#別のデータフレーム作成
questionnaire_s = pd.DataFrame(ss.fit_transform(questionnaire))
fit_transformでヘッダーの情報がなくなるので、コピーする。
#ヘッダー情報のコピー
questionnaire_s.columns = questionnaire.columns
一連を実行すると、以下の結果。

アンケート分析(1):事前準備
時には、主観に惑わされずに、客観的なデータに基づき判断ができるようにデータ分析の訓練を。
アンケートなどで、意見を収集して施策を決めることがあるが、分析までいかずに集計して終わることが多々ある。
アンケートのデータを使用して分析をしてみる。
では、アンケートデータをどうするか?
ダミーデータの作成
こんなエクセルがあればOK。

質問が5個あって、選択肢1~5で回答して、回答者20名にはIDが連番で付与されている。
データがあればよいので、回答は適当にする。
エクセルのセルには以下の数式を入れる
=ROUNDUP(RAND()*5,0)
これで1-5がランダムに作成される。
その後、別シートに値だけ貼り付けてデータ作成完了。
pandasのデータフレームに読みこめば準備完了。
import pandas as pd
questionnaire = pd.read_excel('Book1.xlsx',encoding='UTF-8',index_col='ID')

つ・づ・く